
Note
Go to the end to download the full example code
CatBoost optimization example#
A simple example showing hyperparameter optimization for CatBoost Classifier with genetic algorithms.
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from catboost import CatBoostClassifier
import plotly
import os
from mloptimizer.interfaces import HyperparameterSpaceBuilder, GeneticSearch
from mloptimizer.application.reporting.plots import (plotly_search_space, plotly_logbook,
plot_logbook)
import matplotlib.pyplot as plt
Load and prepare the dataset#
Loading Breast Cancer dataset...
Dataset shape: (569, 30)
Number of classes: 2
Split the data
Define the CatBoost hyperparameter space#
CatBoost has specific hyperparameters that differ from other gradient boosting libraries. We can use the default hyperparameter space or build a custom one.
Option 1: Load default space (recommended for quick start)
hyperparam_space = HyperparameterSpaceBuilder.get_default_space(
estimator_class=CatBoostClassifier
)
# Option 2: Build custom space (uncomment to use)
# hyperparam_space = (HyperparameterSpaceBuilder()
# .add_int_param('depth', min_value=4, max_value=10)
# .add_float_param('learning_rate', min_value=1, max_value=10, scale=100)
# .add_int_param('iterations', min_value=50, max_value=200)
# .add_float_param('subsample', min_value=700, max_value=1000, scale=1000)
# .set_fixed_param('verbose', False)
# .build())
print("\nHyperparameter space configuration:")
print(f"Evolvable parameters: {list(hyperparam_space.evolvable_hyperparams.keys())}")
print(f"Fixed parameters: {list(hyperparam_space.fixed_hyperparams.keys())}")
Hyperparameter space configuration:
Evolvable parameters: ['learning_rate', 'depth', 'n_estimators', 'subsample', 'l2_leaf_reg', 'colsample_bylevel', 'random_strength']
Fixed parameters: ['auto_class_weights', 'bootstrap_type', 'allow_writing_files', 'verbose', 'thread_count']
Configure and run the genetic optimization#
Genetic Algorithm Configuration: - generations: Number of evolutionary iterations - population_size: Number of configurations per generation - n_elites: Number of best individuals preserved each generation - seed: Random seed for reproducibility Note: Small values for faster documentation builds. For production, increase to 20+ generations.
genetic_params = {
'generations': 5,
'population_size': 8,
'n_elites': 2,
'seed': 42,
'use_parallel': False
}
opt = GeneticSearch(
estimator_class=CatBoostClassifier,
hyperparam_space=hyperparam_space,
cv=3,
scoring='accuracy',
disable_file_output=False,
**genetic_params
)
print("\nStarting CatBoost optimization...")
print(f"Generations: {opt.generations}")
print(f"Population size: {opt.population_size}")
# Run the optimization
opt.fit(X_train, y_train)
/home/docs/checkouts/readthedocs.org/user_builds/mloptimizer/checkouts/master/examples/plot_catboost_example.py:76: UserWarning: Some hyperparameters have very small integer ranges (< 10 distinct values): 'depth' (7 values: 4 to 10). Small ranges limit search granularity. Consider increasing the range or scale for float types.
opt = GeneticSearch(
Starting CatBoost optimization...
Generations: 5
Population size: 8
Genetic execution: 0%| | 0/6 [00:00<?, ?it/s, best fitness=?]
Genetic execution: 17%|█▋ | 1/6 [00:05<00:25, 5.20s/it, best fitness=0.974]
Genetic execution: 17%|█▋ | 1/6 [00:06<00:34, 6.86s/it, best fitness=0.976]
Genetic execution: 17%|█▋ | 1/6 [00:40<03:20, 40.19s/it, best fitness=0.978]
Genetic execution: 17%|█▋ | 1/6 [00:53<04:25, 53.03s/it, best fitness=0.978]
Genetic execution: 33%|███▎ | 2/6 [00:53<01:46, 26.51s/it, best fitness=0.978]
Genetic execution: 33%|███▎ | 2/6 [01:18<01:46, 26.51s/it, best fitness=0.98]
Genetic execution: 50%|█████ | 3/6 [01:22<01:23, 27.84s/it, best fitness=0.98]
Genetic execution: 67%|██████▋ | 4/6 [01:29<00:39, 19.86s/it, best fitness=0.98]
Genetic execution: 67%|██████▋ | 4/6 [01:32<00:39, 19.86s/it, best fitness=0.982]
Genetic execution: 83%|████████▎ | 5/6 [01:35<00:15, 15.01s/it, best fitness=0.982]
Genetic execution: 100%|██████████| 6/6 [01:42<00:00, 12.38s/it, best fitness=0.982]
Genetic execution: 100%|██████████| 6/6 [01:48<00:00, 18.15s/it, best fitness=0.982]
/home/docs/checkouts/readthedocs.org/user_builds/mloptimizer/envs/master/lib/python3.11/site-packages/seaborn/_oldcore.py:1119: FutureWarning: use_inf_as_na option is deprecated and will be removed in a future version. Convert inf values to NaN before operating instead.
with pd.option_context('mode.use_inf_as_na', True):
/home/docs/checkouts/readthedocs.org/user_builds/mloptimizer/envs/master/lib/python3.11/site-packages/seaborn/_oldcore.py:1119: FutureWarning: use_inf_as_na option is deprecated and will be removed in a future version. Convert inf values to NaN before operating instead.
with pd.option_context('mode.use_inf_as_na', True):
Get results and evaluate
best_clf = opt.best_estimator_
y_pred = best_clf.predict(X_test)
test_accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='binary')
recall = recall_score(y_test, y_pred, average='binary')
f1 = f1_score(y_test, y_pred, average='binary')
print(f"\nOptimization completed!")
print(f"Best hyperparameters: {opt.best_params_}")
print(f"\nTest performance:")
print(f" Accuracy: {test_accuracy:.4f}")
print(f" Precision: {precision:.4f}")
print(f" Recall: {recall:.4f}")
print(f" F1 Score: {f1:.4f}")
Optimization completed!
Best hyperparameters: {'learning_rate': 0.02, 'depth': 4, 'l2_leaf_reg': 5, 'thread_count': 1, 'verbose': False, 'auto_class_weights': 'Balanced', 'random_strength': 8, 'allow_writing_files': False, 'bootstrap_type': 'Bernoulli', 'subsample': 0.835, 'n_estimators': 479, 'colsample_bylevel': 0.86, 'random_state': 42}
Test performance:
Accuracy: 0.9649
Precision: 0.9722
Recall: 0.9722
F1 Score: 0.9722
Generate visualizations
population_df = opt.populations_
# Search space visualization
top_params = ['depth', 'learning_rate', 'n_estimators', 'l2_leaf_reg', 'fitness']
df_filtered = population_df[top_params]
g_search_space = plotly_search_space(df_filtered, top_params)
g_search_space.update_layout(
title="CatBoost Hyperparameter Search Space - Breast Cancer Dataset",
autosize=True,
width=None,
height=650
)
plotly.io.show(g_search_space, config={'responsive': True})
Simple logbook visualization
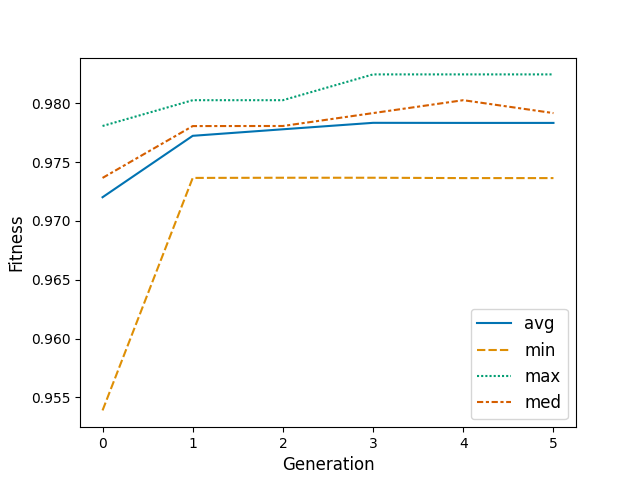
g_logbook_s = plot_logbook(opt.logbook_)
# plt.show() # Commented out for non-interactive environments
/home/docs/checkouts/readthedocs.org/user_builds/mloptimizer/envs/master/lib/python3.11/site-packages/seaborn/_oldcore.py:1119: FutureWarning: use_inf_as_na option is deprecated and will be removed in a future version. Convert inf values to NaN before operating instead.
with pd.option_context('mode.use_inf_as_na', True):
/home/docs/checkouts/readthedocs.org/user_builds/mloptimizer/envs/master/lib/python3.11/site-packages/seaborn/_oldcore.py:1119: FutureWarning: use_inf_as_na option is deprecated and will be removed in a future version. Convert inf values to NaN before operating instead.
with pd.option_context('mode.use_inf_as_na', True):
Evolution logbook visualization
g_logbook = plotly_logbook(opt.logbook_, population_df)
g_logbook.update_layout(
title="CatBoost Optimization Evolution - Breast Cancer Dataset",
autosize=True,
width=None,
height=500
)
plotly.io.show(g_logbook, config={'responsive': True})
Analyze optimization results
print("\n=== Optimization Analysis ===")
print(f"Unique evaluations performed: {opt.n_trials_}")
print(f"Total individuals in population history: {len(population_df)}")
print(f"Optimization time: {opt.optimization_time_:.4f} seconds")
print(f"Time per evaluation: {opt.optimization_time_ / opt.n_trials_:.4f} seconds")
print(f"Generations completed: {opt.generations}")
final_gen = population_df[population_df['population'] == opt.generations]
initial_gen = population_df[population_df['population'] == 1]
final_avg_fitness = final_gen['fitness'].mean()
initial_avg_fitness = initial_gen['fitness'].mean()
improvement = final_avg_fitness - initial_avg_fitness
print(f"\nFitness progression:")
print(f" Initial average fitness: {initial_avg_fitness:.4f}")
print(f" Final average fitness: {final_avg_fitness:.4f}")
print(f" Average improvement: {improvement:.4f}")
=== Optimization Analysis ===
Unique evaluations performed: 28
Total individuals in population history: 48
Optimization time: 109.3850 seconds
Time per evaluation: 3.9066 seconds
Generations completed: 5
Fitness progression:
Initial average fitness: 0.9772
Final average fitness: 0.9783
Average improvement: 0.0011
Access generated files
print("\n=== Generated Files ===")
graphics_path = opt._optimizer_service.optimizer.tracker.graphics_path
results_path = opt._optimizer_service.optimizer.tracker.results_path
print(f"Graphics path: {graphics_path}")
if os.path.exists(graphics_path):
print(" Graphics files:", [f for f in os.listdir(graphics_path) if f.endswith('.html')])
print(f"Results path: {results_path}")
if os.path.exists(results_path):
print(" Results files:", [f for f in os.listdir(results_path) if f.endswith('.csv')])
=== Generated Files ===
Graphics path: ./20260406_230846_CatBoostClassifier/graphics
Graphics files: ['logbook.html', 'search_space.html']
Results path: ./20260406_230846_CatBoostClassifier/results
Results files: ['logbook.csv', 'populations.csv']
CatBoost-specific features#
CatBoost offers several unique features:
Automatic handling of categorical features: No need for manual encoding
Balanced class weights: Set via auto_class_weights=’Balanced’ (included in default space)
GPU acceleration: Add ‘task_type’: ‘GPU’ to fixed parameters
Feature importance: Access via
best_clf.feature_importances_
Example of adding categorical feature support:
# If you have categorical features
cat_features = [0, 2, 4] # Indices of categorical columns
hyperparam_space = (HyperparameterSpaceBuilder()
.add_int_param('depth', 4, 10)
.add_float_param('learning_rate', 1, 10, scale=100)
.set_fixed_param('cat_features', cat_features)
.set_fixed_param('verbose', False)
.build())
Total running time of the script: (1 minutes 51.535 seconds)